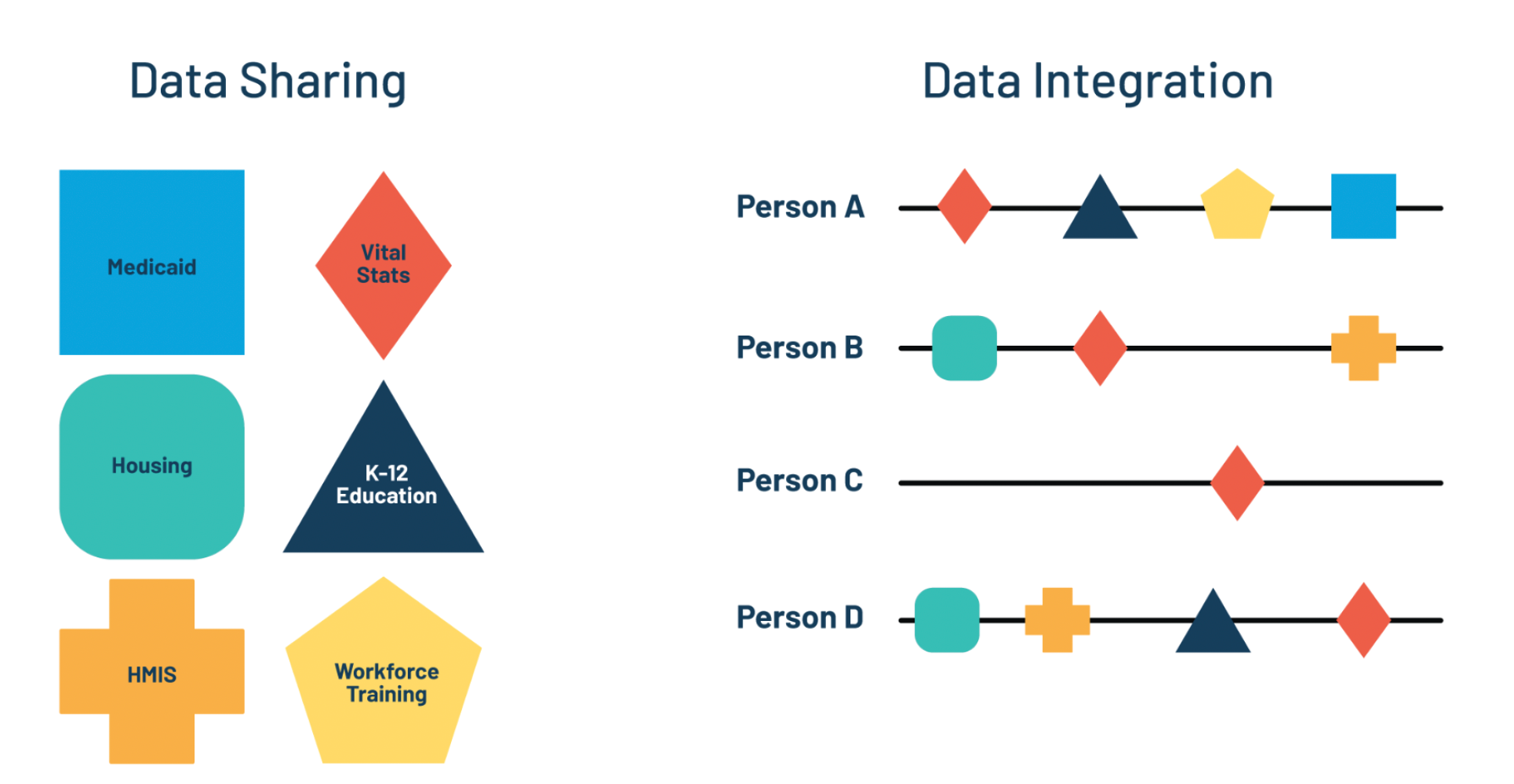
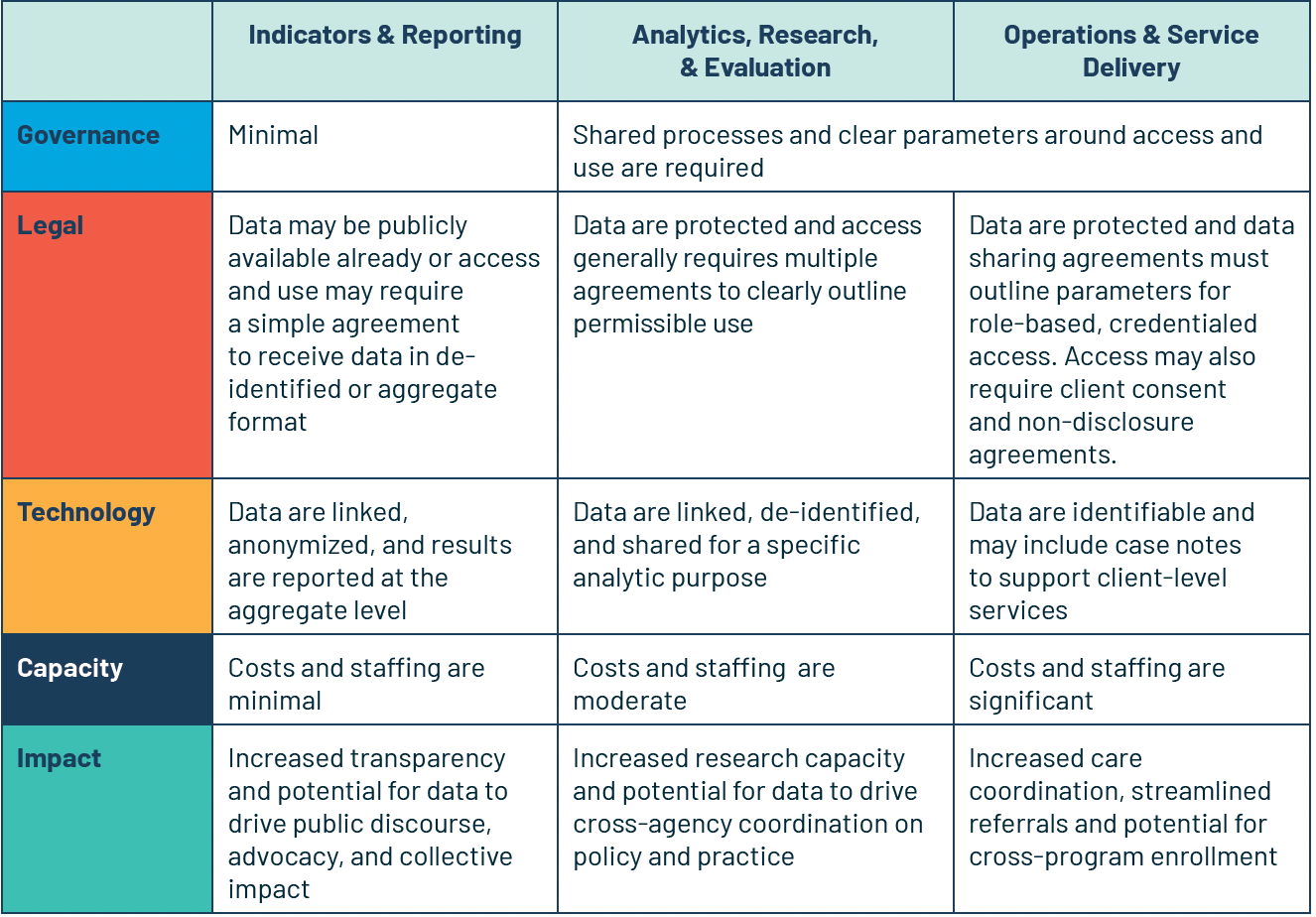
DATA SHARING is the practice of providing partners with access to information (in this case, administrative data) that they cannot access in their own data systems.
DATA INTEGRATION is a more complex type of data sharing that involves record linkage, which refers to the joining or merging of data based on common data fields.